The swish function is a family of mathematical function defined as follows:
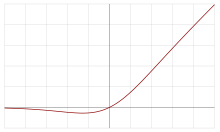
The swish function


where can be constant (usually set to 1) or trainable.
 can be constant (usually set to 1) or
can be constant (usually set to 1) or The swish family was designed to smoothly interpolate between a linear function and the ReLU function.
When considering positive values, Swish is a particular case of doubly parameterized sigmoid shrinkage function defined in . Variants of the swish function include Mish.
Special values
For β = 0, the function is linear: f(x) = x/2.
For β = 1, the function is the Sigmoid Linear Unit (SiLU).
With β → ∞, the function converges to ReLU.
Thus, the swish family smoothly interpolates between a linear function and the ReLU function.
Since , all instances of swish have the same shape as the default , zoomed by . One usually sets . When is trainable, this constraint can be enforced by , where is trainable.
 , all instances of swish have the same shape as the default
, all instances of swish have the same shape as the default  , zoomed by
, zoomed by  . When
. When  , where
, where  is trainable.
is trainable.


Derivatives
Because , it suffices to calculate its derivatives for the default case.so is odd.so is even.
 so
so  is odd.
is odd. so
so  is even.
is even.
History
SiLU was first proposed alongside the GELU in 2016, then again proposed in 2017 as the Sigmoid-weighted Linear Unit (SiL) in reinforcement learning. The SiLU/SiL was then again proposed as the SWISH over a year after its initial discovery, originally proposed without the learnable parameter β, so that β implicitly equaled 1. The swish paper was then updated to propose the activation with the learnable parameter β.
In 2017, after performing analysis on ImageNet data, researchers from Google indicated that using this function as an activation function in artificial neural networks improves the performance, compared to ReLU and sigmoid functions. It is believed that one reason for the improvement is that the swish function helps alleviate the vanishing gradient problem during backpropagation.
References
- ^ Ramachandran, Prajit; Zoph, Barret; Le, Quoc V. (2017-10-27). "Searching for Activation Functions". arXiv:1710.05941v2 .
- Atto, Abdourrahmane M.; Pastor, Dominique; Mercier, Gregoire (March 2008). "Smooth sigmoid wavelet shrinkage for non-parametric estimation". 2008 IEEE International Conference on Acoustics, Speech and Signal Processing (PDF). pp. 3265–3268. doi:10.1109/ICASSP.2008.4518347. ISBN 978-1-4244-1483-3. S2CID 9959057.
- Misra, Diganta (2019). "Mish: A Self Regularized Non-Monotonic Neural Activation Function". arXiv:1908.08681 .
- Hendrycks, Dan; Gimpel, Kevin (2016). "Gaussian Error Linear Units (GELUs)". arXiv:1606.08415 .
- Elfwing, Stefan; Uchibe, Eiji; Doya, Kenji (2017-11-02). "Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning". arXiv:1702.03118v3 .
- Serengil, Sefik Ilkin (2018-08-21). "Swish as Neural Networks Activation Function". Machine Learning, Math. Archived from the original on 2020-06-18. Retrieved 2020-06-18.
| Differentiable computing | |
|---|---|
| General | |
| Hardware | |
| Software libraries | |
| |